


Rediscovering Biology: Molecular to Global Perspectives
Genomics Expert Interview Transcript: Eric S. Lander, Ph.D.

Director, Whitehead Center for Genomic Research and Professor of Biology, MIT.
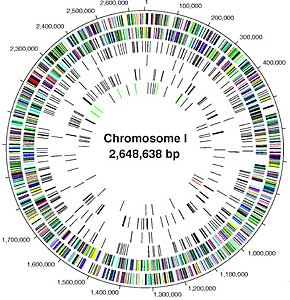
Lander has been one of the principal leaders of the Human Genome Project. As the director of the Whitehead Center for Genomics, Lander has helped to build a series of maps that show the basic layout of the human and mouse genomes. He has published more than 240 original research articles in mathematics, economics, and biology in peer-reviewed journals such as Science, Nature, Cell, Proceedings of the National Academy of Sciences, and The American Journal of Human Genetics. He has also written a book entitled Calculating the Secrets of Life.
Interview Transcript
Lander has been one of the principal leaders of the Human Genome Project. As the director of the Whitehead Center for Genomics, Lander has helped to build a series of maps that show the basic layout of the human and mouse genomes. He has published more than 240 original research articles in mathematics, economics, and biology in peer-reviewed journals such as Science, Nature, Cell, Proceedings of the National Academy of Sciences, and The American Journal of Human Genetics. He has also written a book entitled Calculating the Secrets of Life.
What changes in the field of biology have you seen in the past 10 years?
The whole field of Biology has undergone an amazing revolution in the last ten years. Ten years ago people spent most of their time searching around for one component or another component of the cell, this gene or that gene. In the past ten years, we [now have] complete genomes, the complete catalogs of all the information in cells. It’s not to say we understand it, but it means that the game shifts from the search, rock by rock/pebble, by pebble, to the understanding of the whole landscape and it’s a whole new ballgame.
What were the goals of the Human Genome Project?
I think [the Human Genome Project began] out of a sense of frustration with how slow things were [progressing] without that information.
In 1980, some scientists proposed a way to be able to map the course of a human disease by tracing the inheritance pattern of DNA spelling differences in families. It was a good theoretical idea.
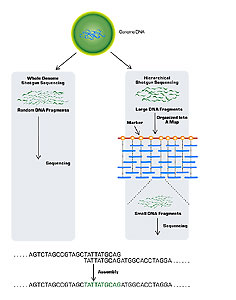
[In the past], a group was able to finally map one disease gene [after four years of research]. Then it’s another ten years before the group was actually able to isolate the disease gene itself by moving along the chromosomes until they finally get there. Again and again, people were running up to the limitations of the huge amount of work it took to answer very simple questions. [What] biologists realized was that if we all got together in a concerted fashion, tried to get all the information at once, it would actually be much more efficient than each person working on his or her own little piece.
How has the field of genomics impacted biology?
[Because the Human Genome Project gave us vast databases], biologists [are able to] think for the first time about completeness, about knowing all the genes. There are many questions you can ask which can only be asked when you have all of something. You can only say, “Hey, there aren’t any genes of this type in the yeast, the fruit fly, or the human” if you’ve got complete lists.
This way we can begin to ask exactly what genes are shared in common between different kinds of organisms, what is our common evolutionary heritage, and what are the innovations that have occurred. It’s a very exciting thing to be able to look at that big picture. I think that’s the change that genomics has brought about, is the ability to look at the big picture.
Very often, what we find is in the fruit fly there is a corresponding gene to the human, which we missed. In fact, it might be very hard to find that gene in the fruit fly by experimental techniques, but in the computer lining up the DNA sequences, we can find the similarities between genes that are, in fact, the distant evolutionary descendants of a common gene, and are probably serving similar functions.
That allows us to take a problem that we’re studying in the human and gain insight from the fruit fly or the mustard weed or in yeast. Twenty-five years ago people studying neurobiology or plants or cancer [had] very little to say to each other.
Now they have a tremendous amount to say to each other because they’re all working with exactly the same toolkit. Often the best way to answer a problem about cancer–cells dividing without [stopping]–is to look at yeast and look at the cell division machinery there. It’s an extraordinary unification.
It used to be that when you were working on a problem, the vast majority of the data that you were studying was data generated on your own lab bench or at most data generated by a few other people in the field. Now increasingly everyone is depending on large communal data sets that have information that bears on every problem.
People [are] now work together in extraordinary ways. Some years ago we cloned a disease gene for a form of dwarfism and when we found the disease gene we needed to know what it did. We put it into the computer, analyzed it, and up popped a gene from a fungus, for example.
[In another example], we cloned a disease gene for a nerve degenerative disorder, put it into the computer, and up popped a gene from a plant. And so in these cases, we [contact] somebody working totally on the other end of biology and say, “what do you know about this gene and this protein?” because suddenly it matters for our problem. Just as often, people call us up and say, “what do you know about something that I’ve just stumbled into?”
How are the lives of people today being touched by genomics?
Well, already we’re beginning to see some of the impacts of genomics, but I think as, with any scientific revolution, [the] real full fruit will take some time to play out. The main impact of genomics, in the long run, will be that we will have an understanding of the mechanism of disease. We spent a lot of the 20th century trying to fight disease without actually knowing what the underlying molecular mechanism was, and so many of the pharmaceuticals that treat disease are simply treating symptoms, not causes.
[Because] genomics gives us the big picture, not just the components, we can begin to figure out where the places [are] to intervene in the course of a disease. I think what it’s going to lead to in the course of the next couple of decades is a much more rational approach to therapy, one validated based on the actual pathways that are present in the human body, rather than what most of medicine had been in the 20th century, which was somewhat lucky accidents.
How has genomics impacted other fields of biology besides medical research?
Well, of course, genomics also tells us many things beyond biomedical sorts of information. It tells us a lot about evolution. It tells us about the unity of all life on this planet. We see the same sets of genes being used and reused across many, many different kinds of organisms. We really begin to understand the tree of evolution in much greater detail by reading whole genomes, which are in effect evolution’s lab notebooks where it’s been taking notes for billions of years.
How different are humans from each other?
One of the things you learn by reading human DNA is that all humans are very similar to each other. Any two human beings are 99.9% identical at the genetic level. That’s actually very, very similar. If you take two chimpanzees in Africa, they’ll differ typically by two or three times as much as any two humans on this planet; two orangutans in Southeast Asia by ten times as much as two humans.
As species go, we’re a very closely related species with only a limited amount of genetic variation, about one part in a thousand-one letter in a thousand-give or take. But that one letter in a thousand does make a huge difference. It accounts for all of the inherited traits we have from people’s tendency to be tall or short, skin color, eye color, hair color, risk of heart disease, risk of hypertension-of course environment [also has an impact] in each of those cases.
In a genome that has three billion letters, one difference in a thousand still means that any two people differ by three million of those positions. There’s more than enough room for a lot of variations that can affect our own physiologies and our own development — and, of course, there’s that great tension between how similar we all are and how very different we all are.
You mentioned single nucleotide differences between humans–can you explain more about these?
If you take the DNA sequence of any two people, they’re almost identical. The DNA bases run along in exactly the same order, except that maybe in one base over here, I might have an “A” on the chromosome that I got from my mom, but a “G” in that position on the chromosome I got from my dad. That’s what we call a single letter difference or a single nucleotide polymorphism [SNP, pronounced “SNIP”].
So as we run along the chromosome every thousand or so bases, we’ll find an SNP and most of these SNPs don’t do anything. They’re just random variations that occurred by a mutation sometime maybe a million years ago or half a million years ago, and they’re just carried in the population.
But sometimes these SNPs will affect the regulation of a gene or the structure of a gene, and then this could be the cause of some people’s risk for Alzheimer’s disease. There are only two SNPs located on chromosome 19 that together determine a reasonable portion of people’s risk for Alzheimer’s disease. If you happen to have inherited a double dose of a particular SNP spelling, you have a much higher risk (about 50%) of Alzheimer’s disease vs. an alternative. So, we’ve all got the same basic double helix but even tiny little differences can sometimes make a huge difference in medical outcome.
How are researchers studying SNPs to further their knowledge of the causes of disease?
Well, once we’ve got a sequence in a human genome, we, of course, want to know about all the variation in that sequence. All of those individual sites of variation, those SNPs, then become points of investigation. We can test each of them to ask how it correlates with the risk of a particular [disease]. In theory, what we’d like to do is run along the genome and take all 6 or 7 or 8 million places in the population where there are common sites of variation and simply write down a big table for each variance. How often does it occur in people with Disease 1, Disease 2, Disease 3, Disease 4– and in some sense describe all of the relationships between human genetic variation and risk of disease in one big matrix. [That] matrix [would] contain all the information about how genetic factors play out in risk of disease.
We’d like to understand the mechanism of how all that works, but it’s possible to imagine collecting that kind of information and trolling it over to say what are the factors that predispose one person with heart disease and another person to diabetes?
This matrix that you described: would this be a map of the human genome?
It turns out that the DNA spelling differences in a given region are actually correlated with each other. If you have a particular set of spellings at one set of positions you’re likely to have another specific set of spellings at the next position over.
In other words, the variations aren’t utterly randomly assorted, but in the regions of the genome–they tend to go together in chunks. We call these chunks “haplotypes.” And really, in a way, it’s not necessary to measure every single variant if we can measure enough of the variants to recognize those chunks or haplotypes.
So one idea is instead of measuring all 6 or 7 million variants in the human population, we might be able to get away with measuring a couple hundred thousand of those variants and [use] them as proxies to fill in all the rest of that variation there.
What is the difference between a restriction fragment length polymorphism (RFLP) and a single nucleotide polymorphism (SNP)?
When you talk about DNA spelling differences, it’s just one common thing-how the DNA sequence varies between people. But the way that you test for that DNA spelling difference depends on the tools you have in your laboratory. Twenty years ago the only way that we could test for a spelling difference was to try to cut the DNA with a restriction enzyme and either it would cut or it wouldn’t cut. That made a restriction fragment length polymorphism, but that was just a technical detail of how you tell if the spelling difference was one or the other.
So when you talk about RFLPs and microsatellites and this and that, they’re all just different ways of [describing] DNA spelling differences. DNA polymorphisms let us track the inheritance of chromosomes in families and in whole populations.
Can you describe the term bioinformatics and explain what it has meant to the field of biology?
The whole intellectual enterprise of writing analysis tools–computer tools–that analyze biological data goes by the somewhat clunky name “bioinformatics.” It’s of course the wonderful science of understanding the great information encoded in biology.
Biology is turning into not just a laboratory science now, but information science, because we have vast databases of DNA sequences, [and] of the patterns of expressions of genes and proteins. We suddenly can’t analyze data with pencil and paper anymore. We have to run computer programs to compare the expression patterns of when genes are turned on and off to say which genes are like each other or to compare their sequences.
How do genomic researchers use bioinformatics?
Well, there are computer programs that can take a stretch of genomic sequence, just the raw DNA of a genome, and predict where there are genes present. Now how good these computer programs are is another question. If you’re dealing with the genome of a small organism, [for] which the genes are big and not interrupted by these little spacers we call introns, the computer programs do a pretty good job.
On the other hand, if you’re dealing with the genome of a mammal, for example, like the human, the genes tend to come in little snippets called exons and they’re separated by pretty big spacers (the introns). The computer programs can get tripped up because the signal-to-noise ratio is pretty low.
And so, in fact, the computer programs don’t do a perfect job. They do a so-so job of taking human DNA and identifying the genes. They do a better job if you’ll give it both human and mouse DNA and let them line it up and then try to look for signals present in both organisms. And I bet when we have the human and the mouse and the rat and the dog and the cow and the cat, it’ll do a mighty fine job because when we get to line up all of the evidence of evolutionary conservation, evolution will have discarded [genes] by virtue of just tinkering with the sequence. Most of the things that don’t matter [get dropped] and the things that do matter [are kept]: this gives the computer more and more power to home in and do a good job of predicting both genes and the other signals that regulate genes.
How does a gene prediction program work?
The programs that try to predict genes look for what we call “splicing sites,” the sites that are used to splice one exon onto another exon in an RNA. We’ve got a little information about the nature of splicing sites. There [are] some consensus sequences, but it’s not an absolutely perfect thing.
So, they also look in between those splicing sites to make sure that the sequence looks like it could encode a protein, that it doesn’t have any stop codons, [and also] that it’s about the right distribution of codons.
It’s a delicate matter, because what it’s really doing is collecting statistical evidence about what tends to occur in genes-the exons of genes, the introns, the splicing sites-and run a statistical model over the DNA to say, “aha, this looks like a plausible gene model.” Of course, life doesn’t do it that way [and] cells don’t run any statistical model. The cell is smart enough to know just where the gene is and where it starts and where it stops and how to splice it.
So to find a gene, the program looks for a start and a stop codon?
Oh, I wish it were as easy as just finding a start and finding a stop. A start codon for a protein is “ATG.” You’re going to bump into a start codon ATG pretty often. [There are] three different reading frames in which I could start, I’m going to find [an ATG] on average about once every 21 bases or so. And yet genes are spaced out [approximately] every 30,000 spaces, so that tells us that less than one in a thousand of the ATGs that get used are actual start codons.
Another bioinformatics tool is the BLAST search: can you explain what this is and how it is used?
One of the first things you want to do when you see a new piece of DNA is [to ask] “what is it similar to?” So you just want to toss it into the computer and [ask the] computer: [have you] ever seen anything like this particular sequence before? And you’d like the computer to do it really fast. It has to look through billions and billions of bases.
There are computer programs that do this search in an extremely fast way. [They] actually make a little look-up table in advance so that they can look up sub-words and get indexes into the vast database of sequence. The most popular program for that goes by the acronym BLAST. It’s such a common word now in biology that people just say, “I’m going to go BLAST that sequence against the database.” I suppose if you’re not used to saying that you have no idea what somebody’s talking about. You assume they’re going to fire some gun at it or something.
What have we learned about genes in particular in the past few years?
Well, [a gene] is really quite remarkable as the unit of the underlying mechanisms of life. The genes that control cellular division in a cancer cell are the same as the genes that control cellular division in a yeast cell. Cell division was invented in nucleated cells some time, oh, about one and a half billion years ago and that same mechanism has been conserved and propagated in all of the nucleated organisms-yeast and plants and animals.
In animals, if we get more specific, [there are] genes that lay out the body plan during development from head to toe and [determine] different segments. Those genes were worked out some time maybe half a billion years ago and have largely been conserved and reused. Evolution’s pretty conservative. When it finds a good solution, it keeps reusing it and we can see it in our genome’s tremendous evidence of that.
You mention that genes are conserved across organisms: how does this help researchers?
Well, one of the most important things that the great conservation of biology does is that it allows us to study a problem like cancer in a yeast or study a problem like a malformation during embryonic development of a human in a fruit fly. We can leap about the tree of life and study problems wherever we have the most convenient set of tools and then translate back answers. It is pretty exciting.
There were other organisms sequenced in the Human Genome Project besides people. The plant Arabidopsis has been sequenced as a model organism: what makes this plant a good candidate?
The best model organism for studying plants is the mustard weed, Arabidopsis thaliana. Its great advantage over most other plants is it’s very little and it grows very fast. If you want to study corn, the best you can do is get three growing cycles in a year and that’s only if you’re willing to grow the winter crops down in Puerto Rico and then come up to Iowa. Whereas you can grow [Arabidopsis] right in your own laboratory and it grows very rapidly and you can get a dozen generations in a year perhaps.
That’s a huge difference if you’re trying to do genetics, especially if you’re an impatient person. Arabidopsis has become a real favorite of people doing plant genetics, just like the fruit fly is a favorite [model organism] of people doing animal genetics.
You have mentioned how computers have changed the way that genomics research is conducted. What other tools have had an impact in the field?
One of the great tools that’s come along with genomics is microarrays. [Microarrays] are slides made of glass or silicon on which you have little detectors for each gene in the genome. Now you might think that’s hard. How do I build a detector for every gene? But genes are double helixes of DNA. If you take one strand of the double helix, it’ll automatically stick to the other strand. So all you have to do is put down on that slide one strand complementary to the first gene, the second gene, the third gene, the fourth gene, the fifth gene, and then you have, in effect, detectors for every gene.
You can take the RNA messages from a cell, wash them over this chip, and they’ll bounce around and find their partners and stick. Gene #92, [for example], will stick to Detector #92. [In a microarray experiment], you label [the sample] fluorescently. [After you have washed the microarray slide], you’ll be able to run a laser across and see the intensity of each spot and thereby infer the amount of each gene that’s been turned on.
What were the surprises that arose from the Human Genome Project?
I think it was something of a surprise to see how unified life was. In the middle of the 20th century maybe people imagined that every branch of life had completely different mechanisms and to find that in fact, all branches of life (certainly all branches of nucleated cells) use the same basic mechanism. I think it was something of a surprise.
Of course in retrospect, it’s perfectly obvious. I mean life isn’t going to go to the trouble of reinventing things. Instead, it reuses things. It slightly modifies them. But I bet if you had gone around and taken a survey back in the 1960s or 1970s and said, “you’re going to find the same basic genes controlling a soil nematode and a fruit fly and a human in terms of their development” or “you are going to find the same basic genes controlling cancer and a baker’s yeast.” I bet most people wouldn’t have voted yes.
What are the unanswered questions in genomics?
Genomics has answered one big question: What are the parts? What it hasn’t yet answered is how they fit together. It’s as if we have the parts list for some vast airplane but we don’t know how to put it together to make an airplane and we don’t understand why it flies.
There’s a tremendous amount left to do. The next generation of students coming along has to take the 30,000 or so parts and put together the wiring diagram that connects them. It’s a tremendous challenge and it’s very exciting. Whole new sets of tools are going to be needed to do that, including tools for going in and interfering with each of those parts so we can see what the effect is on the circuits. As exciting as the Human Genome Project is, it’s of course only the foundation for the great work on biology to come.
What questions would you like students to ask?
My advice to a student today, or to a teacher today, is not to confine themselves to the textbooks. The field is moving so fast that the textbooks are a snapshot of things ten years ago. Get on the web, go explore the websites, the databases. So much more can be learned by looking at one example, visiting the website of a genome center, taking down the data about a particular gene and studying it. Don’t look at the figure in the textbook about how the central dogma works: DNA goes to RNA goes to protein. Go find the insulin gene and look at how it’s encoded, how it’s spliced, how its protein gets made, and processed enclave.
There’s so much data out there at a click of the button that I think students and teachers both should be encouraged to see themselves as part of this vast global biological community. And even if they can’t in their own schools generate the data, they can be using and reading these data.
What moral questions have arisen within this field?
Well, genomics challenges us in providing so much information to think about [and] to use that information responsibly. We can use information to divide people, to say, “that person’s at risk for cancer, let’s not give her insurance for it” or “that person’s at risk for heart disease, I don’t want him to be the president of my company.” Or we can use information to unite us and say, “we all have genetic variation, we’re all at risk for different things, no one chose the particular risks they have. Let’s all pull together. Let’s make sure that each person can use genetic information for their own benefit that no one intrudes into the privacy of other people’s genetic information.”
When biology becomes an information-based science, we have to think very hard about the power of that information and how to make sure that we use it in a way that benefits all of society.
What dream do you have for the future of genomic research?
For me, what I’d really love to see understood is the variation [and] the connection between human genetic variation and human phenotypic variation. That is to connect up the genetic spelling differences with our individual traits: our appearances, our risk of disease, because so much of human variation will shed light on human health and it’s there for the reading. We can almost get at it now. We have the sequence. We know where most of the variation is. What I really want to see is that connection drawn, I can taste it, I can feel it, and yet it’s still some ways off. It’s going to be the work of the next generation of students to get it but I sure want to see that, because life has laid it out for us there in our own DNA codes. The DNA codes of all the members of our species and it’s really there for the reading.]