





Rediscovering Biology: Molecular to Global Perspectives
Proteins and Proteomics Expert Interview Transcript: Aaron Hirsh
 Computational Geneticist
Computational Geneticist
Hirsh is a graduate student in Marcus Fieldman’s lab at Stanford University. His paper on the evolution of protein interactions, in collaboration with Hunter Fraser, was published in the journals of Science and Nature.
Interview Transcript
Hirsh is a graduate student in Marcus Fieldman’s lab at Stanford University. His paper on the evolution of protein interactions, in collaboration with Hunter Fraser, was published in the journals of “Science” and “Nature”.
What would you say was the biggest surprise from Human Genome Project?
A few genomes gave us a nice sense of an increasing number of genes with the complexity of the organism. First, bacteria seemed to have about 5,000; then, yeast seemed to have about 6,000; C. elegans had 19,000. From that trend, people were expecting a hundred thousand genes in humans.
When the genome was finished, what we saw actually was 30,000, a third of what people expected. So suddenly we had to explain how it is that human beings, in all our developmental morphological behavioral complexity, have only about three halves the genes of the nematode which has 950 cells.
So clearly, the complexity of humans was not arising from an increase in the number of genes, but rather from some way in which the genes were talking to each other to create a more complex organism.
How does one explain how humans can be so complex with a genome of approximately 35,000 genes?
How is it that something so complex as the human could arise from 30,000 genes when something so simple as a nematode comes from 19,000 genes?
There are three parts to the answer. First, proteins interact with each other so, with 30,000 proteins, the number of possible interactions is astronomical. The number of interactions increases very rapidly with the total number of genes.
[Another] part of the answer is developmental plans-you can have different stages in which different genes are turned on in humans as you go from a simple embryo to a fully formed human. And the third part of the answer is gene regulation, so genes affect each other not only through the interaction of their proteins, but by turning each other on and off; so a certain gene is making a protein at one point in development, later it’s not.
What our study looked at was the first part-the complexity that can arise through, the interaction of the proteins produced by these 30,000 genes.
Can you talk more about protein interactions?
The cell has a lot of jobs to do. The cell has to take in nutrients, eat those nutrients, digest them-lots of things going on in the cell. Each of those jobs is performed by a whole team of proteins and each of those proteins has a different job. The protein team performs its job cooperatively-one individual protein interacts with the second protein, [which] changes its confirmation in some way so that the second protein can go on and speak to a third protein to change its confirmation in some way. So there are messages passed from one protein to another and there are cooperative structures formed where one protein will actually combine with another so that the two can do something together that either one could not have done individually.
What did you find out about how protein interactions and evolution?
One main result [of our research] was that proteins that interact with each other tend to change at the same rate so if A is evolving at some rate, and A interacts with B, we found [that] B tends to evolve at the same rate as A. Why would that be? Our explanation for that is that each time a change takes place in A, it requires a reciprocal change in B so that the dialogue between the two proteins can be maintained-this interaction is allowing the proteins to perform some function.
When A changes, it disturbs their interaction; they can no longer perform their function. [But if] A changes, [and] B changes in a compensatory way to restore their dialogue, they can perform their function again. So natural selection favors the compensatory change and we recover this original function of the two. You can imagine that happening not only once-A changes, B changes in return-but again and again. You have this ongoing co-evolutionary cycle.
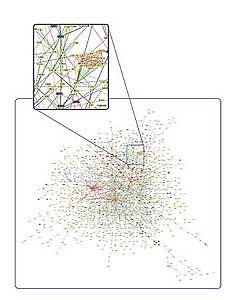
[I previously mentioned] the increase in complexity of the interaction network. Clearly, humans with 30,000 genes must have a much more complicated network of interactions than does C. elegans with 19,000 proteins; otherwise how could humans be so different from C. elegans? It’s not just due to 10,000 more genes. We need more than that.
We have to ask, how do you add new interactions? How can you put a new protein into the interaction network? Or how can Protein A, that’s already talking to Protein B, start talking to [another protein] if it has to do this job with B?
Well, if they’re static-if A and B are stuck-that probably can’t happen. But if A can change a little bit to allow it to start talking to C, then B can change a little bit to maintain its dialogue with A.
What was your theory of how proteins evolve?
People thought that proteins that had lots of jobs to do-lots of interactions-would be more constrained and they had that idea because they looked at individual proteins.
There were a few examples of co-evolution between proteins, individual pairs of proteins where you would see one protein changing and the other protein changing in response.
What we’re doing now is something made possible by genomic data-that is, we can look for the traces of that kind of co-evolution throughout the whole genome. We don’t have to focus on a single pair of proteins. We can ask: Do we see this pattern of co-evolution or do we see a trace of co-evolution everywhere in the genome or is it just in these couple examples? And we found that it’s everywhere. It’s a trend that’s quite widespread. It’s not just one or two proteins.
What specific question were you trying to answer?
We wanted to know whether proteins that interact co-evolve. We wanted to look for the traces left by co-evolution on the genome, and so the way we would test for that we decided is to look to see whether proteins that interact evolve at similar rates because if they do co-evolve then pairs that interact should evolve at the same rate.
What led you to ask this particular question and conduct this study?
There were a couple of reasons. One, protein interaction data became available so it became possible. Why were we interested in doing it? Molecular biology and molecular evolution have made huge amounts of progress obviously but they have been required to look at one protein at a time, focus on one pathway at a time.
That doesn’t incorporate much of the complexity of the organism. So if you want to start to address the question: how do you get from yeast to worm, it’s going to be hard to do that looking at one protein at a time, because these are changes that are happening at the organismal level.
So we wanted [to] move from a focus on single proteins that allow you to address questions about cellular function or protein function, to questions about all proteins and the complete network of protein interactions. We thought that kind of broader question would give us a better chance of understanding the kinds of processes that take you from yeast to worm. And I assume those are the same processes that take you from worm to human.
What was the methodology of your study?
The study started with gathering lots of data. We needed to know how many other proteins any given protein interacts with. So basically we [chose] Yeast Protein A. [Then] we needed a list of all the proteins that Yeast Protein A interacts with. And [then we had to] do the same thing for every single protein in yeast-there are 6,000 proteins-so that was compiling a lot of data generated by other people.
The second kind of data we needed was information on the rates at which proteins change. Together, those two pieces of information would allow us to address the question we wanted to address. Do proteins that interact evolve at similar rates? So we needed to estimate the rate at which each protein changes.
We took the yeast genome, [and] we took a distant relative, the worm, and we asked: how different is this yeast protein from its closest relative in [the] worm? We used that difference to estimate how fast that protein has been changing along its evolutionary descent.
Then we had protein interaction data, how many interactions does each protein participate in, and we had protein evolutionary rates. Then it was simply using statistics to investigate whether the pairs of proteins that interact have similar rates of evolution. And that was largely a computational project.
Were there any obstacles to your study?
Our biggest problem early on was in estimating the rate at which each yeast protein evolved. We needed an estimate for a large number of proteins because we wanted to look at [this] on a genome-wide scale. The problem is for each estimate, we needed a protein in another species that we could compare it to. The only other organism we had with a huge number of genes sequenced that we could use for comparison with [yeast] was C. elegans. C. elegans was a billion years of evolution away so it’s very likely that lots of changes in protein function have taken place, [and] lots of proteins have been lost. So that left us with very little hope that we would detect any pattern at all. But we thought we’d give it a try because it was the only organism available for the comparison at that time.
We were trying to look for a pattern in a billion years of evolution which is a little bit like trying to detect the remnants of the Big Bang in the radiation that we receive from outer space. There’s very little of it there because it’s been a very, very long time.
At what point in your study did you know you had hit upon something?
When we saw that there was, in fact, a pattern-that in fact proteins that interact do evolve at similar rates, we were definitely shocked that we could see it, surprised that we could see it-so surprised that we sort of didn’t believe it initially. We thought, well, it must be due to something else, so we went through a number of alternative explanations trying to determine whether those alternative explanations could explain why we were seeing what we were seeing. And eventually, we convinced ourselves that none of those stood up.
Was a BLAST search a part of your study?
[Yes], first we took a yeast protein and we blasted it against the worm. [After] we get a best hit for that Blast search, we blast it back against the yeast genome and if we hit the same yeast sequence that we started with, we call those “two reciprocal best hits.”
Evolutionary models show you that reciprocal best hits are much more likely to be closest relatives than are Blast hits that turn out not to be reciprocal.
So we took a yeast gene, blasted it against worm, took our top five, and then for each of those top five, we did some more analysis to determine evolutionary distance back to yeast. Then we did the same thing in reverse and that time we looked for nearest evolutionary neighbors, rather than reciprocal best hits, which is slightly different only because we’re not relying totally on Blast. We’re actually trying to reconstruct evolutionary distance rather than just looking for similarity. Blast just looks for similarity.
How does natural selection relate to your study?
The way [that] we’re looking for the traces of selection in this study is this. If two proteins interact (A interacts with B), and A changes a little bit, it disrupts that interaction. That organism with a slightly disrupted interaction between A and B doesn’t do as well as the organism without the disrupted interaction.
If the descendants of that organism experienced a second change, that is B changes, it [could] restore this interaction between A and B. Then those individuals that have a restored interaction between A and B will be more fit. They’ll be healthier than the ones that have disturbed interaction between A and B.
Selection favors the individuals that have the restored interaction. As a result, you have the reciprocal change in B increasing in the population, and you have a co-evolutionary step completed. So selection shows up in favoring the reciprocal changes between proteins.
How does this protein selection fit in with Darwin’s work?
Darwin, in most of his examples of evolution in The Origin of Species, are examples in which one organism interacts with another; and changes in one of those organisms selects for changes in the other organism.
Darwin was very focused on co-evolution. He paid much less attention to the ways in which organisms evolve to suit the weather than he did to the ways in which organisms evolve to suit each other. That is, the hummingbird evolves to feed on a particular flower. The flower evolves to be pollinated by the hummingbird. He wrote whole books on the ways in which orchids are fertilized.
We wanted to take that same vision of evolution in which different entities are changing in response to each other and apply it within the organism. Darwin was thinking about the ways whole organisms change in response to each other. We are now thinking within an organism, how individual proteins change in response to each other.
We see the same result at two very different scales. Natural selection is very good at adapting one organism to its way of life and interaction with other organisms. It’s also very good at adapting each molecule to its interaction with other molecules. So the co-evolutionary process that Darwin saw, the scale of whole organisms is what we see at the scale of individual proteins.
Can you talk about the complexity of your study?
It was difficult because of the huge amount of evolutionary change separating the organisms. It was complex because the protein interaction network is very complex.
We tried to incorporate some of that complexity into our study [by] looking at pairs of interacting proteins, but there [is] still a huge amount of organization and complexity in the yeast. So, the study was complex, but it wasn’t complex enough. [That is], it doesn’t rival the complexity of the system we’re studying at this point.
So your study differed from other evolutionary studies because they conducted research on an organism level?
There was another branch of biology looking at [evolutionary] change on the scale of the organism. How does the shape of the organism change? How does the size of the organism change? How does the behavior of the organism change?
We’re looking at one molecule. The hope now is that we’re going to look at many complex interactions among molecules and start to understand the way those complex interactions affect change at the level of the entire organism.
There’s still going to be changes that are easier to understand at the level of the organism. All of organismal biology is not going to [be] reduced to understanding proteins, but we may start to understand rules about how proteins change, rules about how all proteins evolve, that will tell us something about what’s underpinning the organismal changes observed by a different area of biology.
Have you done any follow-up research to your original study?
Initially, the only organism we had for comparison with the yeast proteins was C. elegans. We were shocked that we could find a pattern with such a distant comparison.
And by the same token, [we were not] sure once we had seen that pattern over a billion years of evolution that we would see it over a hundred million years of evolution. When we could find close relatives to yeast to compare our proteins to, we weren’t sure that we would still see the result. We were actually a little nervous that we wouldn’t see the result because if you had to choose between [using] a billion-year-old separation for your comparison or a hundred million years, you would much rather use the closer one.
Since doing the study, we’ve had the chance to analyze progressively closer evolutionary comparisons. There’s another yeast species called Candida albicans-we’ve done that and some more close genomes. Each one has revealed the same pattern. The evolutionary process seems to operate at every time scale.
What are your unanswered questions?
We have some sense of how pairs of proteins evolve in communication with each other in this ongoing dialogue of change.
We still don’t understand so much about how you can add interactions to produce more complex organisms. We’re pretty sure that adding interactions, changing your interaction network, is a big part of the story. We’re pretty sure that humans have a more complex protein interaction network than do worms.
But we really can’t say much about how the simpler network of worms was transformed to give us the more complex network of humans. Our study sort of suggests that since proteins are co-evolving, you can add new proteins. It allows for the addition of more proteins to the network. But, if more proteins are added, that doesn’t tell you really how you get from a worm to a human.
How will the field of proteomics help with this kind of research?
I think there are a lot of questions that are newly accessible because of the new proteomic data. I think that the study of whole genomes and the proteins they encode, does hold promise for bridging the gap in explanation between our very thorough understanding of simple molecular systems in the cell and the whole functioning organism. We’re going to have to learn to read the interaction of molecules in the way that we don’t know how to read them [now]: But we’re starting to understand more points along this continuum from molecular circuit to functioning organism, which is not to say we’re reducing the organism to a set of molecular circuits. We’re just learning to explain processes that are underpinned by molecules at a scale that is getting closer to the whole organism.