














The Habitable Planet: A Systems Approach to Environmental Science
Many Planets, One Earth Online Textbook
1. Introduction
Unit 1 // Section 1
Earth’s long history tells a story of constant environmental change and of close connections between physical and biological environments. It also demonstrates the robustness of life. Simple organisms first appeared on Earth some 3.8 billion years ago, and complex life forms emerged approximately 2 billion years ago. Life on Earth has endured through many intense stresses, including ice ages, warm episodes, high and low oxygen levels, mass extinctions, huge volcanic eruptions, and meteorite impacts. Untold numbers of species have come and gone, but life has survived even the most extreme fluxes.
To understand why Earth has been so conducive to life, we need to identify key conditions that make it habitable and ask why they exist here but not on neighboring planets. This unit describes how Earth’s carbon cycle regulates its climate and keeps surface temperatures within a habitable range. It also examines another central factor: the rise of free oxygen in the atmosphere starting more than 2 billion years ago. Next we briefly survey the evolution of life on Earth from simple life forms through the Cambrian explosion and the diversification of multicellular organisms—including, most recently, humans. This unit also describes how scientists find evidence in today’s geologic records for events that took place millions or even billions of years ago (Fig. 1).

Geologist Paul Hoffman points out glacial dropstones, small rounded pebbles imbedded in otherwise neat layers of sedimentary rock 500-600 million years old.
Figure 1. Evidence of glaciation in seaside rocks, Massachusetts
Humans are latecomers in geologic time: when Earth’s history is mapped onto a 24-hour time scale, we appear less than half a minute before the clock strikes midnight (footnote 1). But even though humans have been present for a relatively short time, our actions are changing the environment in many ways, which are addressed in units 5 through 13 of this course. Life on Earth will persist in spite of these human impacts. But it remains to be seen how our species will manage broad-scale challenges to our habitable planet, especially those that we create. As history shows, Earth has maintained conditions over billions of years that are uniquely suitable for life on Earth, but those conditions can fluctuate widely. Human impacts add to a natural level of ongoing environmental change.
2. Many Planets, One Earth
Unit 1 // Section 2
Our solar system formed from a solar nebula, or cloud of gas and dust, that collapsed and condensed about 4.56 billion years ago. Most of this matter compacted together to form the sun, while the remainder formed planets, asteroids, and smaller bodies. The outer planets, Jupiter, Saturn, Uranus, and Neptune, condensed at cold temperatures far from the sun. Like the sun, they are made mostly of hydrogen and helium. In contrast, the terrestrial planets, Mercury, Venus, Earth and Mars, formed closer to the sun where temperatures were too high to allow hydrogen and helium to condense. Instead they contain large amounts of iron, silicates (silicon and oxygen), magnesium, and other heavier elements that condense at high temperatures.
The young Earth was anything but habitable. Radioactive elements decaying within its mass and impacts from debris raining down from space generated intense heat—so strong that the first eon of Earth’s history, from about 4.5 to 3.8 billion years ago, is named the Hadean after hades, the Greek word for hell. Most original rock from this period was melted and recycled into Earth’s crust, so very few samples remain from our planet’s formative phase. But by studying meteorites—stony or metallic fragments up to 4.5 billion years old that fall to Earth from space—scientists can see what materials were present when the solar system was formed and how similar materials may have been melted, crystallized, and transformed as Earth took shape (Fig. 2).

Figure 2. The Willamette Meteorite, the largest ever found in the United States (15 tons)
Source: © Denis Finnin, American Museum of Natural History.
About 4 billion years ago, conditions on Earth gradually began to moderate. The planet’s surface cooled, allowing water vapor to condense in the atmosphere and fall back as rain. This early hydrologic cycle promoted rock weathering, a key part of the carbon-silicate cycle that regulates Earth’s climate (discussed in section 4). Evidence from ancient sediments indicates that oceans existed on Earth as long ago as 3.5 billion years.
Conditions evolved very differently on adjoining planets. Venus, which has nearly the same size and density as Earth and is only about 30 percent closer to the sun, is sometimes referred to as our “sister planet.” Scientists once thought that conditions on Venus were much like those on Earth, just a little bit warmer. But in reality Venus is a stifling inferno with an average surface temperature greater than 460°C (860°F). This superheated climate is produced by Venus’s dense atmosphere, which is about 100 times thicker than Earth’s atmosphere and is made up almost entirely of carbon dioxide (CO2) (Fig. 3). As we will see in Unit 2, “Atmosphere,” CO2 is a greenhouse gas that traps heat reflected back from planetary surfaces, warming the planet. To make conditions even more toxic, clouds on Venus consists mainly of sulfuric acid droplets.
Paradoxically, if Venus had an atmosphere with the same composition as Earth’s, Venus would be colder even though it is closer to the sun and receives approximately twice as much solar radiation as Earth does. This is because Venus has a higher albedo(its surface is brighter than Earth’s surface), so it reflects a larger fraction of incoming sunlight back to space. Venus is hot because its dense atmosphere functions like a thick blanket and traps this outgoing radiation. An atmosphere with the same makeup as Earth’s would function like a thinner blanket, allowing more radiation to escape back to space (Fig. 3).
 Figure 3. Comparison of Venus and Earth
Figure 3. Comparison of Venus and Earth
Source: Courtesy NASA/JPL-Caltech.
Mars is not much farther from the sun than Earth, but it is much colder. Clouds of ice and frozen CO2 (dry ice) drift over its surface. Frozen ice caps at the poles, which can be seen from Earth with a telescope, reflect sunlight. Although Mars’s atmosphere consists mainly of CO2, it is 100 times thinner than Earth’s atmosphere, so it provides only a small warming effect. Early in its history, the “Red Planet” had an atmosphere dense and warm enough to sustain liquid water, and it may even have had an ocean throughout its northern hemisphere. Today, however, all water on Mars is frozen.
Why is Venus so hot? Why is Mars so cold? And why has the Earth remained habitable instead of phasing into a more extreme state like Mars or Venus? The key difference is that an active carbon cycle has kept Earth’s temperature within a habitable range for the past 4 billion years, despite changes in the brightness of the sun during that time. This process is described in detail in section 4, “Carbon Cycling and Earth’s Climate.” Moderate surface temperatures on Earth have created other important conditions for life, such as a hydrologic cycle that provides liquid water.
How unique are the conditions that allowed life to develop and diversify on Earth? Some scientists contend that circumstances on Earth were extremely unusual and that complex life is very unlikely to find such favorable conditions elsewhere in our universe, although simple life forms like microbes may be very common (footnote 2). Other scientists believe that Earth’s history may not be the only environment in which life could develop, and that other planets with very different sets of conditions could foster complex life. What is generally agreed, however, is that no other planet in our solar system has developed along the same geologic and biologic path as Earth. Life as we know it is a direct result of specific conditions that appear thus far to be unique to our planet.
3. Reading Geologic Records
Unit 1 // Section 3
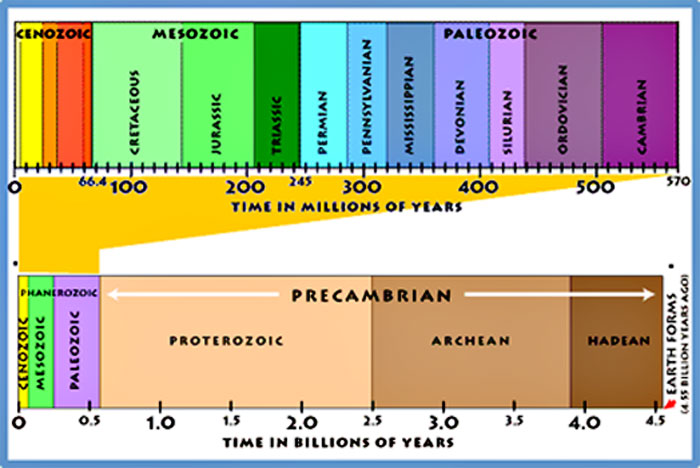
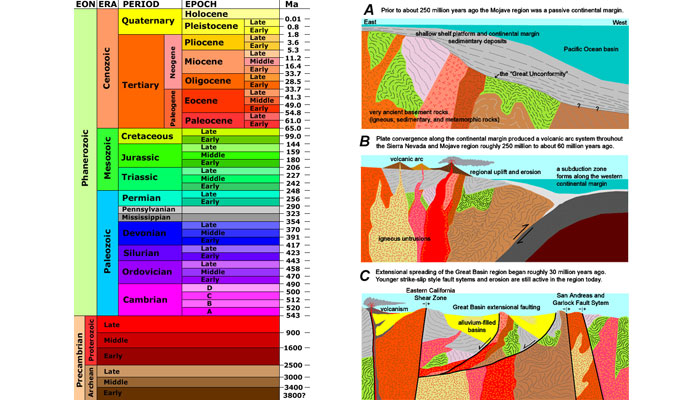
Scientists have divided Earth’s history into a series of time segments that are collectively referred to as the geologic time scale (Figure 4). Each of these units is defined based on geologic and fossil records, with divisions between the units marking some major change such as the appearance of a new class of living creatures or a mass extinction. Geologic time phases become shorter as we move forward from Earth’s formation toward the present day because records grow increasingly rich. Newer rocks and fossils are better preserved than ancient deposits, so more information is available to categorize recent phases in detail and pinpoint when they began and ended.

Figure 4. The geologic time scale
Source: © United States Geological Survey.
Most of what we know about our planet’s history is based on studies of the stratigraphic record—rock layers and fossil remains embedded in them. These rock records can provide insights into questions such as how geological formations were created and exposed, what role was played by living organisms, and how the compositions of oceans and the atmosphere have changed through geologic time.
Scientists use stratigraphic records to determine two kinds of time scales. Relative time refers to sequences—whether one incident occurred before, after, or at the same time as another. The geologic time scale shown in Figure 4 reads upwards because it is based on observations from sedimentary rocks, which accrete from the bottom up (wind and water lay down sediments, which are then compacted and buried). However, the sedimentary record is discontinuous and incomplete because plate tectonics are constantly reshaping Earth’s crust. As the large plates on our planet’s surface move about, they split apart at some points and collide or grind horizontally past each other at others. These movements leave physical marks: volcanic rocks intrude upward into sediment beds, plate collisions cause folding and faulting, and erosion cuts the tops off of formations thrust up to the surface.
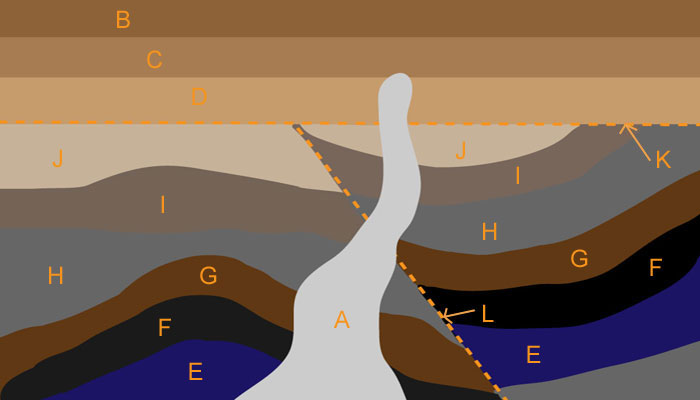
Geologists have some basic rules for determining relative ages of rock layers. For example, older beds lie below younger beds in undisturbed formations, an intruding rock is younger than the layers it intrudes into, and faults are younger than the beds they cut across. In the geologic cross-section shown in Figure 5, layers E, F, G, H, I, and J were deposited through sedimentation, then cut by faults L and K, then covered by layers D, C, and B. A is a volcanic intrusion younger than the layers it penetrates.

Geologic cross-sections are vertical slices through rock formations. Earth scientists analyze cross-sections to map an area’s geological history.
Figure 5. Sample geologic cross-section
Scientists also use fossil records to determine relative age. For example, since fish evolved before mammals, a rock formation at site A that contains fish fossils is older than a formation at site B that contains mammalian fossils. And environmental changes can leave telltale geologic imprints in rock records. For example, when free oxygen began to accumulate in the atmosphere, certain types of rocks appeared for the first time in sedimentary beds and others stopped forming (for more details, see section 6, “Atmospheric Oxygen”). Researchers study mineral and fossil records together to trace interactions between environmental changes and the evolution of living organisms.
Until the early twentieth century, researchers could only assign relative ages to geologic records. More recently, the expanding field of nuclear physics has enabled scientists to calculate the absolute age of rocks and fossils using radiometric dating, which measures the decay of radioactive isotopes in rock samples. This approach has been used to determine the ages of rocks more than 3.5 billion years old (footnote 3). Once they establish the age of multiple formations in a region, researchers can correlate strata among those formations to develop a fuller record of the entire area’s geologic history (Fig. 6).

© United States Geological Survey, Western Earth Surface Processes Team.
Figure 6. Geologic history of southern California
Our understanding of Earth’s history and the emergence of life draws on other scientific fields along with geology and paleontology. Biologists trace genealogical relationships among organisms and the expansion of biological diversity. And climate scientists analyze changes in Earth’s atmosphere, temperature patterns, and geochemical cycles to determine why events such as ice ages and rapid warming events occurred. All of these perspectives are relevant because, as we will see in the following sections, organisms and the physical environment on Earth have developed together and influenced each other’s evolution in many ways.
4. Carbon Cycling and Earth's Climate
Unit 1 // Section 4
How did early Earth transition from a hell-like environment to temperatures more hospitable to life? Early in the Archean (ancient) eon, about 3.8 billion years ago, the rain of meteors and rock bodies from space ended, allowing our planet’s surface to cool and solidify. Water vapor in the atmosphere condensed and fell as rain, creating oceans. These changes created the conditions for geochemical cycling—flows of chemical substances between reservoirs in Earth’s atmosphere, hydrosphere (water bodies), and lithosphere (the solid part of Earth’s crust).
At this time the sun was about 30 percent dimmer than it is today, so our planet received less solar radiation. Earth’s surface should have been well below the freezing point of water, too cold for life to exist, but evidence shows that liquid water was present and that simple life forms appeared as far back as 3.5 billion years ago. This contradiction is known as the “faint young sun” paradox (Fig. 7). The unexpected warmth came from greenhouse gases in Earth’s atmosphere, which retained enough heat to keep the planet from freezing over.

Figure 7. The faint, young sun and temperatures on Earth
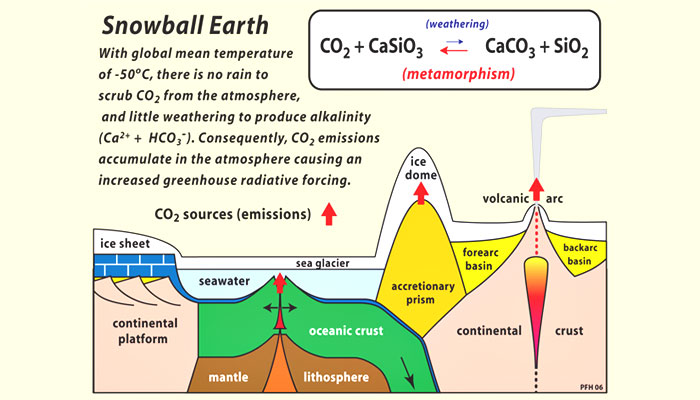
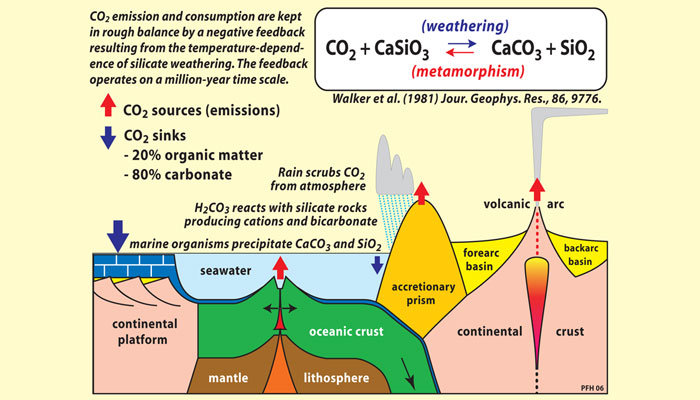
The Archean atmosphere was a mix of gases including nitrogen, water vapor, methane (CH4), and CO2. (As discussed in section 6, “Atmospheric Oxygen,” free oxygen did not accumulate in the atmosphere until more than two billion years after Earth was formed.) Volcanoes emitted CO2 as a byproduct of heating within the Earth’s crust. But instead of developing a runaway greenhouse effect like that on Venus, Earth’s temperatures remained within a moderate range because the carbon cycle includes a natural sink—a process that removes excess carbon from the atmosphere. This sink involves the weathering of silicate rocks, such as granites and basalts, that make up much of Earth’s crust.
As illustrated in Figure 8, this process has four basic stages. First, rainfall scrubs CO2out of the air, producing carbonic acid (H2CO3), a weak acid. Next, this solution reacts on contact with silicate rocks to release calcium and other cations and leave behind carbonate and biocarbonate ions dissolved in the water. This solution is washed into the oceans by rivers, and then calcium carbonate (CaCO3), also known as limestone, is precipitated in sediments. (Today most calcium carbonate precipitation is caused by marine organisms, which use calcium carbonate to make their shells.) Over long time scales, oceanic crust containing limestone sediments is forced downward into Earth’s mantle at points where plates collide, a process called subduction. Eventually, the limestone heats up and turns the limestone back into CO2, which travels back up to the surface with magma. Volcanic activity then returns CO2 to the atmosphere.

Figure 8. The geochemical carbon cycle
Source: © Snowball Earth.org.
Many climatic factors influence how quickly this process takes place. Warmer temperatures speed up the chemical reactions that take place as rocks weather, and increased precipitation may flush water more rapidly through soil and sedimentary rocks. This creates a negative feedback relationship between rock weathering and climatic changes: when Earth’s climate warms or cools, the system responds in ways that moderate the temperature change and push conditions back toward equilibrium, essentially creating a natural thermostat.
For example, when the climate warms, weathering rates accelerate and convert an increasing fraction of atmospheric CO2 to calcium carbonate, which is buried on the ocean floor. Atmospheric concentrations of CO2 decline, modifying the greenhouse effect and cooling Earth’s surface. In the opposite instance, when the climate cools weathering slows down but volcanic outgassing of CO2 continues, so atmospheric CO2levels rise and warm the climate.
This balance between CO2 outgassing from volcanoes and CO2 conversion to calcium carbonate through silicate weathering has kept the Earth’s climate stable through most of its history. Because this feedback takes a very long time, typically hundreds of thousands of years, it cannot smooth out all the fluctuations like a thermostat in one’s home. As a result, our planet’s climate has fluctuated dramatically, but it has never gone to permanent extremes like those seen on Mars and Venus.
Why is Venus a runaway greenhouse? Venus has no water on its surface, so it has no medium to dissolve CO2, form carbonic acid, and react with silicate rocks. As a result volcanism on Venus continues to emit CO2 without any carbon sink, so it accumulates in the atmosphere. Mars may have had such a cycle early in its history, but major volcanism stopped on Mars more than 3 billion years ago, so the planet eventually cooled as CO2 escaped from the atmosphere. On Earth, plate tectonics provides continuing supplies of the key ingredients for the carbon-silicate cycle: CO2, liquid water, and plenty of rock.
5. Testing the Thermostat: Snowball Earth
Unit 1 // Section 5
We can see how durable Earth’s silicate weathering “thermostat” is by looking at some of the most extreme climate episodes on our planet’s history: severe glaciations that occurred during the Proterozoic era. The first “Snowball Earth” phase is estimated to have occurred about 2.3 billion years ago, followed by several more between about 750 and 580 million years ago. Proponents of the Snowball Earth theory believe that Earth became so cold during several glacial cycles in this period that it essentially froze over from the equator to the poles for spans of ten million years or more. But ultimately, they contend, the carbon-silicate cycle freed Earth from this deep-freeze state.
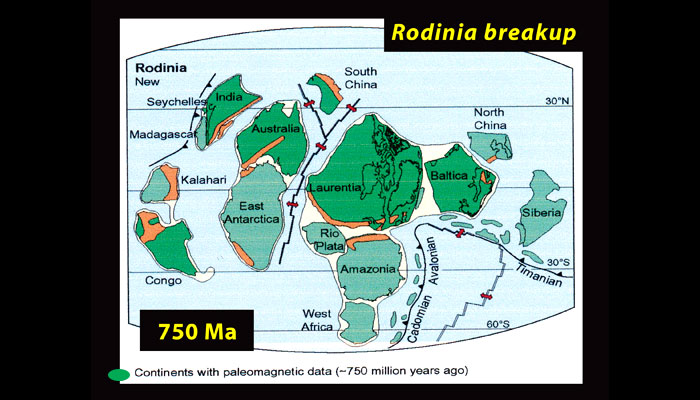
If Earth has a natural thermostat, how could it become cold enough for the entire planet to freeze over? One possible cause is continental drift. Researchers believe that around 750 million years ago, most of the continents may have been clustered in the tropics following the breakup of the supercontinent Rodinia (Fig. 9), and that such a configuration would have had pronounced effects on Earth’s climate (footnote 4).

Figure 9. The breakup of Rodinia
Source: © Snowball Earth.org.
Had the continents been located closer to the poles as they are today, ice sheets would have developed at high latitudes as the planet cooled. Ice cover would prevent the rocks beneath from weathering, thus slowing the rate at which carbon was removed from the atmosphere and allowing CO2 from volcanic eruptions to build up in the atmosphere. As a result, Earth’s surface temperature would warm.
But if continents were clustered at low latitudes, Earth’s land masses would have remained ice-free for a long time even as ice sheets built up in the polar oceans and reflected a growing fraction of solar energy back to space. Because most continental area was in the tropics, the weathering reactions would have continued even as the Earth became colder and colder. Once sea ice reached past about 30 degrees latitude, Snowball Earth scholars believe that a runaway ice-albedo effect occurred: ice reflected so much incoming solar energy back to space, cooling Earth’s surface and causing still more ice to form, that the effect became unstoppable. Ice quickly engulfed the planet and oceans froze to an average depth of more than one kilometer.
The first scientists who imagined a Snowball Earth believed that such a sequence must have been impossible, because it would have cooled Earth so much that the planet would never have warmed up. Now, however, scientists believe that Earth’s carbon cycle saved the planet from permanent deep-freeze. How would a Snowball Earth thaw? The answer stems from the carbon-cycle thermostat discussed earlier.
Even if the surface of the Earth was completely frozen, volcanoes powered by heat from the planet’s interior would continue to vent CO2. However, very little water would evaporate from the surface of a frozen Earth, so there would be no rainfall to wash CO2 out of the atmosphere. Over roughly 10 million years, normal volcanic activity would raise atmospheric CO2 concentrations by a factor of 1,000, triggering an extreme warming cycle (Fig. 10). As global ice cover melted, rising surface temperatures would generate intense evaporation and rainfall. This process would once again accelerate rock weathering, ultimately drawing atmospheric CO2 levels back down to normal ranges.

Figure 10. The geochemical carbon cycle on a Snowball Earth
Source: © Snowball Earth.org.
Many geologic indicators support the snowball glaciation scenario. Glacial deposits (special types of sediments known to be deposited only by glaciers or icebergs) are found all around the world at two separate times in Earth’s history: once around 700 million years ago and then again around 2,200 million years ago. In both cases some of these glacial deposits have magnetic signatures that show that they were formed very close to the equator, supporting an extreme glacial episode.
Another important line of evidence is the existence of special iron-rich rocks, called iron formations, that otherwise are seen only very early in Earth’s history when scientists believe that atmospheric oxygen was much lower. In the presence of oxygen, iron exists as “ferric” iron (Fe3+), a form that is very insoluble in water (there is less than one part per billion of iron dissolved in seawater today). However, before oxygen accumulated in the atmosphere, iron would have existed in a reduced state, called “ferrous” iron (Fe2+), which is readily dissolved in seawater. Geologists believe that iron formations were produced when iron concentrations in the deep ocean were very high but some oxygen existed in the surface ocean and atmosphere. Mixing of iron up from the deep ocean into the more oxidized ocean would cause the chemical precipitation of iron, producing iron formations.
Geologists do not find iron formations after about 1.8 billion years ago, once oxygen levels in the atmosphere and ocean were high enough to remove almost all of the dissolved iron. However, iron formations are found once again around 700 million years ago within snowball glacial deposits. The explanation appears to be that during a Snowball Earth episode sea ice formed over most of the ocean’s surface, making it difficult for oxygen to mix into the water. Over millions of years iron then built up in seawater until the ice started to melt. Then atmospheric oxygen could mix with the ocean once again, and all the iron was deposited in these unusual iron formations (Fig. 11).

Figure 11. Banded iron formation from Ontario, Canada
Source: ©Denis Finnin, American Museum of Natural History.
The Snowball Earth is still a controversial hypothesis. Some scientists argue that the evidence is not sufficient to prove that Earth really did freeze over down to the equator. But the hypothesis is supported by more and more unusual geological observations from this time, and also carries some interesting implications for the evolution of life.
How could life survive a snowball episode? Paradoxically, scientists theorize that these deep freezes may have indirectly spurred the development of complex life forms. The most complex life forms on Earth at the time of the Neoproterozoic glaciations were primitive algae and protozoa. Most of these existing organisms were undoubtedly wiped out by glacial episodes. But recent findings have shown that some microscopic organisms can flourish in extremely challenging conditions—for example, within the channels inside floating sea ice and around vents on the ocean floor where superheated water fountains up from Earth’s mantle. These environments may have been the last reservoirs of life during Snowball Earth phases. Even a small amount of geothermal heat near any of the tens of thousands of natural hot springs that exist on Earth would have been sufficient to create small holes in the ice. And those holes would have been wonderful refuges where life could persist.
Organisms adaptable enough to survive in isolated environments would have been capable of rapid genetic evolution in a short time. The last hypothesized Snowball Earth episode ended just a few million years before the Cambrian explosion, an extraordinary diversification of live that took place from 575 to 525 million years ago (discussed in section 8, “Multi-Celled Organisms and the Cambrian Explosion”). It is possible, although not proven, that the intense selective pressures of snowball glaciations may have fostered life forms that were highly adaptable and ready to expand quickly once conditions on Earth’s surface moderated.
6. Atmospheric Oxygen
Unit 1 // Section 6
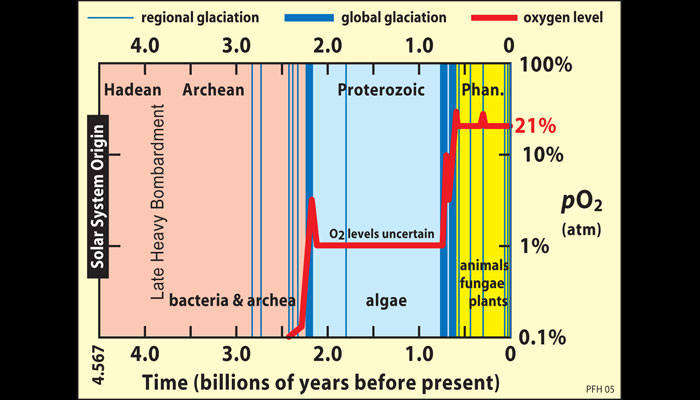
A stable climate is only one key requirement for the complex life forms that populate Earth today. Multi-cellular organisms also need a ready supply of oxygen for respiration. Today oxygen makes up about 20 percent of Earth’s atmosphere, but for the first two billion years after Earth formed, its atmosphere was anoxic (oxygen-free). About 2.3 billion years ago, oxygen increased from a trace gas to perhaps one percent of Earth’s atmosphere. Another jump took place about 600 million years ago, paving the way for multi-cellular life forms to expand during the Cambrian Explosion.
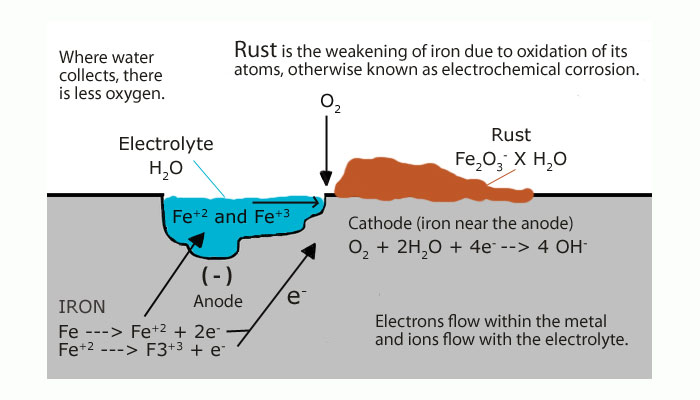
Oxygen is a highly reactive gas that combines readily with other elements like hydrogen, carbon, and iron. Many metals react directly with oxygen in the air to form metal oxides. For example, rust is an oxide that forms when iron reacts with oxygen in the presence of water. This process is called oxidation, a term for reactions in which a substance loses electrons and become more positively charged. In this case, iron loses electrons to oxygen (Fig. 12). What little free oxygen was produced in Earth’s atmosphere during the Archean eon would have quickly reacted with other gases or with minerals in surface rock formations, leaving none available for respiration.

In oxidation reactions such as rust formation, a molecule or atom loses electrons and becomes more positively charged. Although it
Figure 12. Oxidation of iron to form rust
Geologists trace the rise of atmospheric oxygen by looking for oxidation products in ancient rock formations. We know that very little oxygen was present during the Archean eon because sulfide minerals like pyrite (fool’s gold), which normally oxidize and are destroyed in today’s surface environment, are found in river deposits dating from that time. Other Archean rocks contain banded iron formations (BIFs)—the sedimentary beds described in section 5 that record periods when waters contained high concentrations of iron. These formations tell us that ancient oceans were rich in iron, creating a large sink that consumed any available free oxygen.
Scientists agree that atmospheric oxygen levels increased about 2.3 billion years ago to a level that may have constituted about 1 percent of the atmosphere. One indicator is the presence of rock deposits called red beds, which started to form about 2.2 billion years ago and are familiar to travelers who have visited canyons in Arizona or Utah. These strata of reddish sedimentary rock, which formed from soils rich in iron oxides, are basically the opposite of BIFs: they indicate that enough oxygen had accumulated in the atmosphere to oxidize iron present in soil. If the atmosphere had still been anoxic, iron in these soils would have remained in solution and would have been washed away by rainfall and river flows. Other evidence comes from changes in sulfur isotope ratios in rocks, which indicate that about 2.4 billion years ago sulfur chemistry changed in ways consistent with increasing atmospheric oxygen.
Why did oxygen levels rise? Cyanobacteria, the first organisms capable of producing oxygen through photosynthesis, emerged well before the first step up in atmospheric oxygen concentrations, perhaps as early as 2.7 billion years ago. Their oxygen output helped to fill up the chemical sinks, such as iron in soils, that removed oxygen from the air. But plant photosynthesis alone would not have provided enough oxygen to account for this increase, because heterotrophs (organisms that are not able to make their own food) respire oxygen and use it to metabolize organic material. If all new plant growth is consumed by animals that feed on living plants and decomposers that break down dead plant material, carbon and oxygen cycle in what is essentially a closed loop and net atmospheric oxygen levels remain unchanged (Fig. 13).

Photosynthesis removes CO2 from the air and adds oxygen, while cellular respiration removes oxygen from the air and adds CO2. The processes generally balance each other out.
Figure 13. Cycling of carbon and oxygen
However, material can leak out of this loop and alter carbon-oxygen balances. If organic matter produced by photosynthesis is buried in sediments before it decomposes (for example, dead trees may fall into a lake and sink into the lake bottom), it is no longer available for respiration. The oxygen that decomposers would have consumed as they broke it down goes unused, increasing atmospheric oxygen concentrations. Many researchers theorize that this process caused the initial rise in atmospheric oxygen.
Some scientists suspect that atmospheric oxygen increased again about 600 million years ago to levels closer to the composition of our modern atmosphere. The main evidence is simply that many different groups of organisms suddenly became much larger at this time. Biologists argue that it is difficult for large, multicellular animals to exist if oxygen levels are extremely low, as such animals cannot survive without a fairly high amount of oxygen. However, scientists are still not sure what caused a jump in oxygen at this time.
One clue may be the strange association of jumps in atmospheric oxygen with snowball glaciations. Indeed, the jumps in atmospheric oxygen at 2.3 billion years ago and 600 million years ago do seem to be associated with Snowball Earth episodes (Fig. 14). However, scientists are still unsure exactly what the connection might be between the extreme ice ages and changes in the oxygen content of the atmosphere.

Figure 14. Atmospheric oxygen levels over geological time
Source: © Snowball Earth.org.
Why have atmospheric oxygen levels stayed relatively stable since this second jump? As discussed above, the carbon-oxygen cycle is a closed system that keeps levels of both elements fairly constant. The system contains a powerful negative feedback mechanism, based on the fact that most animals need oxygen for respiration. If atmospheric oxygen levels rose substantially today, marine zooplankton would eat and respire organic matter produced by algae in the ocean at an increased rate, so a lower fraction of organic matter would be buried, canceling the effect. Falling oxygen levels would reduce feeding and respiration by zooplankton, so more of the organic matter produced by algae would end up in sediments and oxygen would rise again. Fluctuations in either direction thus generate changes that push oxygen levels back toward a steady state.
Forest fires also help to keep oxygen levels steady through a negative feedback. Combustion is a rapid oxidation reaction, so increasing the amount of available oxygen will promote a bigger reaction. Rising atmospheric oxygen levels would make forest fires more common, but these fires would consume large amounts of oxygen, driving concentrations back downward.
7. Early Life: Single-Celled Organisms
Unit 1 // Section 7
We do not know exactly when life first appeared on Earth. There is clear evidence that life existed at least 3 billion years ago, and the oldest sediments that have been discovered—rocks formed up to 3.8 billion years ago—bear marks that some scientists believe could have been left by primitive microorganisms. If this is true it tells us that life originated soon after the early period of bombardment by meteorites, on an Earth that was probably much warmer than today and had only traces of oxygen in its atmosphere.
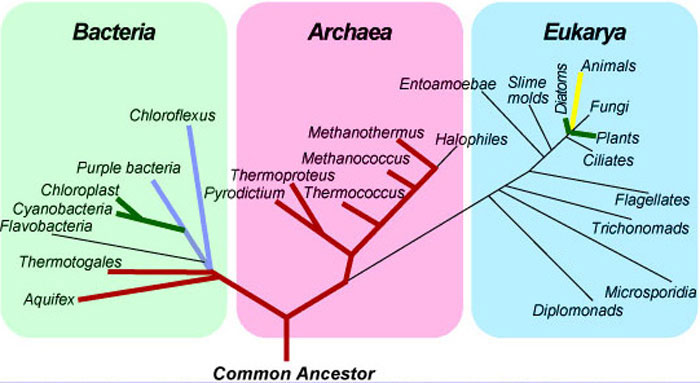
For the first billion years or so, life on Earth consisted of bacteria and archaea, microscopic organisms that represent two of the three genealogical branches on the Tree of Life (Fig. 15). Both groups are prokaryotes (single-celled organisms without nuclei). Archaea were recognized as a unique domain of life in the 1970s, based on some distinctive chemical and genetic features. The order in which branches radiate from the Tree of Life shows the sequence in which organisms evolved. Reading from the bottom up in the same way in which a tree grows and branches outward, we can see that eucarya (multi-celled animals) were the last major group to diverge and that animals are among the newest subgroups within this domain.

Figure 15.The universal Tree of Life
Source: © Jack D. Farmer, 2000. Hydrothermal Systems: Doorways to Early Biosphere Evolution, GSA Today 10(7), 1-9.
Life on Earth existed for many millions of years without atmospheric oxygen. The lowest groups on the Tree of Life, including thermatogales and nearly all of the archaea, are anaerobic organisms that cannot tolerate oxygen. Instead they use hydrogen, sulfur, or other chemicals to harvest energy through chemical reactions. These reactions are key elements of many chemical cycles on Earth, including the carbon, sulfur, and nitrogen cycles. “Prokaryotic metabolisms form the fundamental ecological circuitry of life,” writes paleontologist Andrew Knoll. “Bacteria, not mammals, underpin the efficient and long-term functioning of the biosphere” (footnote 5).
Some bacteria and archaea are extremophiles—organisms that thrive in highly saline, acidic, or alkaline conditions or other extreme environments, such as the hot water around hydrothermal vents in the ocean floor. Early life forms’ tolerances and anaerobic metabolisms indicate that they evolved in very different conditions from today’s environment.
Microorganisms are still part of Earth’s chemical cycles, but most of the energy that flows through our biosphere today comes from photosynthetic plants that use light to produce organic material. When did photosynthesis begin? Archaean rocks from western Australia that have been dated at 3.5 billion years old contain organic material and fossils of early cyanobacteria, the first photosynthetic bacteria (footnote 6). These simple organisms jump-started the oxygen revolution by producing the first traces of free oxygen through photosynthesis: Knoll calls them “the working-class heroes of the Precambrian Earth” (footnote 7).
Cyanobacteria are widely found in tidal flats, where the organic carbon that they produced was buried, increasing atmospheric oxygen concentrations. Mats of cyanobacteria and other microbes trapped and bound sediments, forming wavy structures called stromatolites (layered rocks) that mark the presence of microbial colonies (Fig. 16).

Figure 16. Stromatolites at Hamelin Pool, Shark Bay, Australia
Source: © National Aeronautics and Space Administration, JSC Astrobiology Institute.
The third domain of life, eukaryotes, are organisms with one or more complex cells. A eukaryotic cell contains a nucleus surrounded by a membrane that holds the cell’s genetic material. Eukaryotic cells also contain organelles—sub-components that carry out specialized functions such as assembling proteins or digesting food. In plant and eukaryotic algae cells, chloroplasts carry out photosynthesis. These organelles developed through a process called endosymbiosis in which cyanobacteria took up residence inside host cells and carried out photosynthesis there. Mitochondria, the organelles that conduct cellular respiration (converting energy into usable forms) in eukaryotic cells, are also descended from cyanobacteria.
The first eukaryotic cells evolved sometime between 1.7 and 2.5 billion years ago, perhaps coincident with the rise in atmospheric oxygen around 2.3 billion years ago. As the atmosphere and the oceans became increasingly oxygenated, organisms that used oxygen spread and eventually came to dominate Earth’s biosphere. Chemosynthetic organisms remained common but retreated into sediments, swamps, and other anaerobic environments.
Throughout the Proterozoic era, from about 2.3 billion years ago until around 575 million years ago, life on Earth was mostly single-celled and small. Earth’s biota consisted of bacteria, archaea, and eukaryotic algae. Food webs began to develop, with amoebas feeding on bacteria and algae. Earth’s land surfaces remained harsh and largely barren because the planet had not yet developed a protective ozone layer (this screen formed later as free oxygen increased in the atmosphere), so it was bombarded by intense ultraviolet radiation. However, even shallow ocean waters shielded microorganisms from damaging solar rays, so most life at this time was aquatic.
As discussed in sections 5 and 6, global glaciations occurred around 2.3 billion years ago and again around 600 million years ago. Many scientists have sought to determine whether there is a connection between these episodes and the emergence of new life forms around the same times. For example, one Snowball Earth episode about 635 million years ago is closely associated with the emergence of multicellularity in microscopic animals (footnote 8). However, no causal relationship has been proved.
8. The Cambrian Explosion and the Diversification of Animals
Unit 1 // Section 8
The first evidence of multicellular animals appears in fossils from the late Proterozoic era, about 575 million years ago, after the last snowball glaciation. These impressions were made by soft-bodied organisms such as worms, jellyfish, sea pens, and polyps similar to modern sea anemones (Fig. 17). In contrast to the microorganisms that dominated the Proterozoic era, many of these fossils are at least several centimeters long, and some measure up to a meter across.

Figure 17. Fossils of Kimberella (thought to be a jellyfish)
Source: Courtesy Wikimedia Commons. GNU Free Documentation License.
Shortly after this time, starting about 540 million years ago, something extraordinary happened: the incredible diversification of complex life known as the Cambrian Explosion. Within 50 million years every major animal phylum known in fossil records quickly appeared. The Cambrian Explosion can be thought of as multicellular animals’ “big bang”—an incredible radiation of complexity.
What triggered the Cambrian Explosion? Scientists have pointed to many factors. For example, the development of predation probably spurred the evolution of shells and armor, while the growing complexity of ecological relationships created distinct roles for many sizes and types of organisms. Rising atmospheric and oceanic oxygen levels promoted the development of larger animals, which need more oxygen than small ones in order to move blood throughout their bodies. And some scientists believe that a mass extinction at the end of the Proterozoic era created a favorable environment for new life forms to evolve and spread.
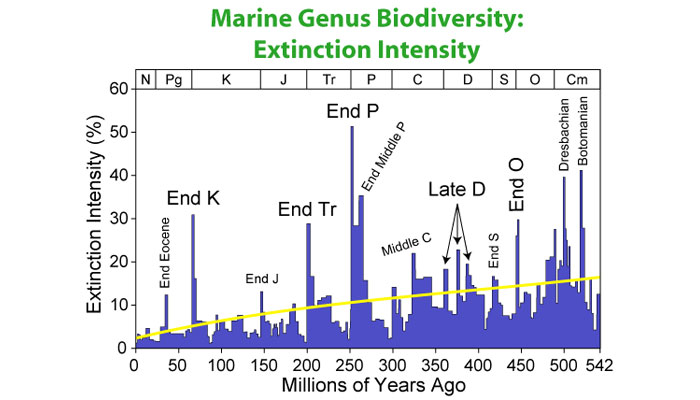
Following the Cambrian Explosion, life diversified in several large jumps that took place over three eras: Paleozoic, Mesozoic, and Cenozoic (referring back to Fig. 4, the Cambrian period was the first slice of the Paleozoic era). Together these eras make up the Phanerozoic eon, a name derived from the Greek for “visible life.” The Phanerozoic, which runs from 540 million years ago to the present, has also been a tumultuous phase in the evolution of life on Earth, with mass extinctions at the boundaries between each of its three geologic eras. Figure 18 shows the scale of historic mass extinctions as reflected in marine fossil records.

Figure 18. Marine genus biodiversity
Source: © Wikimedia Commons. Courtesy Dragons Flight. GNU Free Documentation License.
Early in the Paleozoic most of Earth’s fauna lived in the sea. Many Cambrian organisms developed hard body parts like shells and bones, so fossil records became much more abundant and diverse. The Burgess Shale, rock beds in British Columbia made famous in paleontologist Stephen Jay Gould’s book Wonderful Life, are ancient reef beds in the Canadian Rockies of British Columbia that are filled with fossil deposits from the mid-Cambrian period (footnote 9).
Land plants emerged between about 500 and 400 million years ago. Once established, they stabilized soil against erosion and accelerated the weathering of rock by releasing chemicals from their roots. Since faster weathering pulls increased amounts of carbon out of the atmosphere, plants reduced the greenhouse effect and cooled Earth’s surface so dramatically that they are thought to have helped cause several ice ages and mass extinctions during the late Devonian period, about 375 million years ago. By creating shade, they also provided habitat for the first amphibians to move from water to land.
The most severe of all mass extinctions took place at the end of the Paleozoic era at the Permian/Triassic boundary, wiping out an estimated 80 to 85 percent of all living species. Scientists still do not understand what caused this crisis. Geologic records indicate that deep seas became anoxic, which suggest that something interfered with normal ocean mixing, and that Earth’s climate suddenly became much warmer and drier. Possible causes for these developments include massive volcanic eruptions or a melting of methane hydrate deposits (huge reservoirs of solidified methane), both of which could have sharply increased the greenhouse effect.
The Mesozoic era, spanning the Triassic, Jurassic, and Cretaceous periods, was the era of reptiles, which colonized land and air more thoroughly than the amphibians that preceded them out of the water. Dinosaurs evolved in the Triassic, about 215 million years ago, and became the largest and most dominant animals on Earth for the next 150 million years. This period also saw the emergence of modern land plants, including the first angiosperms (flowering plants); small mammals; and the first birds, which evolved from dinosaurs. Figure 19 shows a model of a fossilized Archaeopteryx, a transitional species from the Jurassic period with both avian and dinosaur features.

Figure 19. Model of Archaeopteryx fossil
Source: © Wikimedia Commons. CeCILL license.
Another mass extinction at the end of the Mesozoic, 65 million years ago, killed all of the dinosaurs except for birds, along with many other animals. For many years scientists thought that climate change caused this extinction, but in 1980 physicist Louis Alvarez, his son, Walter, a geologist, and other colleagues published a theory that a huge meteorite had hit Earth, causing impacts like shock waves, severe atmospheric disturbances, and a global cloud of dust that would have drastically cooled the planet. Their most important evidence was widespread deposits of iridium—a metal that is extremely rare in Earth’s crust but that falls to Earth in meteorites—in sediments from the so-called K-T (Cretaceous-Tertiary) boundary layer.
Further evidence discovered since 1980 supports the meteor theory, which is now widely accepted. A crater has been identified at Chicxulub, in Mexico’s Yucatan peninsula, that could have been caused by a meteorite big enough to supply the excess iridium, and grains of shocked quartz from the Chicxulub region have been found in sediments thousands of kilometers from the site that date to the K-T boundary era.
9. The Age of Mammals
Unit 1 // Section 9
The first mammals on Earth were rodent-sized animals that evolved in the shadow of dinosaurs during the Jurassic and Triassic periods. After the K-T boundary extinction eliminated dinosaurs as predators and competitors, mammals radiated widely. Most of the modern mammal orders, from bats to large types like primates and whales, appeared within about 10 million years after dinosaurs died out. Because mammals could maintain a relatively constant internal temperature in hot or cold environments, they were able to adapt to temperature changes more readily than cold-blooded animals like reptiles, amphibians, and fish. This characteristic helped them to populate a wide range of environments.
Another important ecological shift was the spread of angiosperms (flowering plants), which diversified and became the dominant form of land plants. Unlike earlier plants like ferns and conifers, angiosperms’ seeds were enclosed within a structure (the flower) that protected developing embryos. Their flower petals and fruits, which grew from plants’ fertilized ovaries, attracted animals, birds, and insects that helped plants spread by redistributing pollen and seeds. These advantages enabled angiosperms to spread into more diverse habitats than earlier types of plants.
Earth’s climate continued to fluctuate during the Cenozoic, posing challenges for these new life forms. After an abrupt warming about 55 million years ago, the planet entered a pronounced cooling phase that continued up to the modern era. One major cause was the ongoing breakup of Gondwanaland, a supercontinent that contained most of the land masses in today’s southern hemisphere, including Africa, South America, Australia, and India (Fig. 20).

Figure 20. Gondwanaland
Source: ©United States Geological Survey.
Once these fragments started to separate about 160 million years ago, ocean currents formed around Antarctica. Water trapped in these currents circulated around the pole and became colder and colder. As a result, Antarctica cooled and developed a permanent ice cover, which in turn cooled global atmospheric and ocean temperatures. Climates became dryer, with grasslands and arid habitat spreading into many regions that previously had been forested.
Continued cooling through the Oligocene and Miocene eras, from about 35 million to 5 million years ago, culminated in our planet’s most recent ice age: a series of glacial advances and retreats during the Pleistocene era, starting about 3.2 million years ago (Fig. 21). During the last glacial maximum, about 20,000 years ago, ice sheets covered most of Canada and extended into what is now New England and the upper Midwestern states.

Figure 21. Cenozoic cooling
Source: © Global Warming Art. GNU License/www.globalwarmingart.com.
Human evolution occurred roughly in parallel with the modern ice age and was markedly influenced by geologic and climate factors. Early hominids (members of the biological family of the great apes) radiated from earlier apes in Africa between 5 and 8 million years ago. Humans’ closest ancestor, Australopithecus, was shorter than modern man and is thought to have spent much of its time living in trees. The human genus, Homo, which evolved about 2.5 million years ago, had a larger brain, used hand tools, and ate a diet heavier in meat than Australopithecus. In sum, Homo was better adapted for life on the ground in a cooler, drier climate where forests were contracting and grasslands were expanding.
By 1.9 million years ago, Homo erectus had migrated from Africa to China and Eurasia, perhaps driven partly by climate shifts and resulting changes to local environments. Homo sapiens, the modern human species, is believed to have evolved in Africa about 200,000 years ago. Homo sapiens gradually migrated outward from Africa, following dry land migration routes that were exposed as sea levels fell during glacial expansions. By about 40,000 years ago Homo sapiens had settled Europe, and around 10,000 years ago man reached North America. Today, archaeologists, anthropologists, and geneticists are working to develop more precise maps and histories of the human migration out of Africa, using mitochondrial DNA (maternally inherited genetic material) to assess when various areas were settled.
Early in their history, humans found ways to manipulate and affect their environment. Mass extinctions of large mammals, such as mammoths and saber-toothed cats, occurred in North and South America, Europe, and Australia roughly when humans arrived in these areas. Some researchers believe that over-hunting, alone or in combination with climate change, may have been the cause. After humans depleted wildlife, they went on to domesticate animals, clear forests, and develop agriculture, with steadily expanding impacts on their surroundings that are addressed in units 5 through 12 of this text.
10. Further Reading and Footnotes
Unit 1 // Section 10
Further Reading
University of California Museum of Paleontology, Web Geological Time Machine, http://www.ucmp.berkeley.edu/help/timeform.html.
An era-by-era guide through geologic time using stratigraphic and fossil records.
Science Education Resource Center, Carleton College, “Microbial Life in Extreme Environments,” http://serc.carleton.edu/microbelife/extreme/index.html.
An online compendium of information about extreme environments and the microbes that live in them.
National Geographic, “A Map of Human Migration,” https://genographic.nationalgeographic.com/human-journey/.
An interactive map showing human migration with links to more in depth information.
Footnotes
- American Museum of Natural History, “Our Dynamic Planet: Rock Around the Clock,” http://www.amnh.org/education/resources/rfl/web/earthmag/peek/pages/clock.htm.
- Peter D. Ward and Donald Brownlee, Rare Earth: Why Complex Life Is Uncommon in the Universe (New York: Springer-Verlag, 2000).
- U.S. Geological Survey, “Radiometric Time Scale,” http://pubs.usgs.gov/gip/geotime/radiometric.html, and “The Age of the Earth,” http://geology.wr.usgs.gov/parks/gtime/ageofearth.html.
- Paul F. Hoffman and Daniel P. Schrag, “Snowball Earth,” Scientific American, January 2000, pp. 68–75.
- Andrew Knoll, Life on a Young Planet: The First Three Billion Years of Evolution on Earth (Princeton University Press, 2003), p. 23.
- University of California Museum of Paleontology, “Cyanobacteria: Fossil Record,” http://www.ucmp.berkeley.edu/bacteria/cyanofr.html.
- Knoll, Life on a Young Planet, p. 42.
- “Did the Snowball Earth Kick-Start Complex Life?”, http://www.snowballearth.org/kick-start.html.
- Stephen Jay Gould, Wonderful Life: The Burgess Shale and the Nature of History (New York: Norton, 1990).